Empowering Everybody to be DevOps
The Shutl engineering team has been operating with a DevOps mentality for over two years. We started by rebuilding our infrastructure under Chef and embedding our operations engineers into our agile product development process.
We made great progress and saw a big improvement in delivery and quality as all team members were responsible for getting things live and ensuring their long-term maintainability. But… we still had a silo. Only a few of our team were doing the lion’s share of the work when it came to maintaining our infrastructure, and on-call duties were shared by just a small number of people.
Over the past six months, we’ve changed that. So, rather than extol the virtues of this approach – there are plenty of articles doing that! – we thought we’d share some of the steps we took to make every engineer a DevOps engineer.
PairOps
In a lot of cases, a DevOps team is an antipattern. I don’t think this is always the case – sometimes you have a large amount of technical debt in your infrastructure, and a dedicated project team to clear things up is a good idea. And, if you’re transitioning from a systems team model as we were, this isn’t a bad place to start – but we aspired to more.
First, we broke down the DevOps team and put the engineers into our project teams, making them more aligned to product and feature goals, and no team was reliant on another to get things done.
The next step was to bring pairing into DevOps – in fact, we even renamed the discipline as “PairOps” – meaning that our operations engineers would pair within their teams on tasks like building EC2 boxes, writing chef recipes and debugging issues.
Configuration management systems like Chef are often esoteric in implementation, and the debugging skills that operations engineers learn over many years can’t just be picked up in a few days. We invested in training actively, every day, through pairing.
This knowledge sharing was invaluable in improving the quality of our Chef codebase and building new systems, and also gave rise to our deployment pipeline, based on RunDeck. At this point, we started deploying 100+ times a week.
Within just a few weeks, the number of engineers who could actively work on AWS and Chef recipes had tripled.
Training
If you’ve never built a Linux box before, or fiddled with database configuration or worked with other parts of a production system like load balancing, it’s worth spending time learning – this is specialist knowledge, not simple and not always intuitive. I can remember the blind panic in my early days of cloud computing when I logged on and could see no instances – at all. It took me a few seconds to realise I was looking in the wrong region, but this moment reminds me that in an area such as operations you have a lot of opportunities to make big, scary, mistakes, and that undermines confidence quickly!
We created individual accounts for every engineer on our cloud hosting provider, and spent time training people on how to use the administration systems. Pairing on real features helped us grow understanding and nurture confidence, and also had the side benefit of teaching our operations specialists how to pair more effectively, another silo we were able to break down.
It’s easy to be overwhelmed by the variety in operations work, so we quantified our knowledge weaknesses with a gap analysis. This was a simple shared document listing every component and typical tasks, one per row, and then a column for each team member to answer a simple question: “are you comfortable doing this task”.
We took the clusters of “no” answers and addressed them with informal training sessions, ran by one of our engineers. The training covered areas such as restoring data backups or working with mongodb replicasets. These were easy to deliver and associated documentation was produced, allowing us to tailor the training to what the team needed, rather than devising a large curriculum.
First-Class Treatment for Operations Tasks
A team is more than a group of people sat together – it requires a sense of shared direction and ownership of tasks. As part of this we have one Trello board, giving visibility on every task that our team is working on. If somebody is sick or unavailable, the team ensures their colleague’s card is not neglected and attempt to keep all the work progressing.
It was time to give operations tasks this same treatment. We made the operations backlog visible to everyone and made the tasks first class citizens in and amongst the story cards on our Trello board. We prioritised in a way that made sense against the other work that was going on.
With this in mind, we added operations features to Pivotal Tracker, where we keep all our backlogs. They were then prioritised in our planning meetings along with our user stories. We then break features down into tasks and put them onto our main Trello board, the same as we do with all our other features. As well as making it easier to know what was being worked on, this also made it easier for the team to pair up on the work – it’s obvious when somebody is working solo when the card is discussed in the standup, and that’s the perfect time to volunteer to pair.
On-Call
Out of hours, the team maintains the system and responds to alerts. Our alerting configuration was pretty good, but it wasn’t clean – false alerts were frequent and it was easy to ignore alerts that you knew weren’t important. Whilst ignoring is easy, working to reduce the amount of false alerts isn’t when you operate in an operations silo, as you’re dependent on other teams to make your life easier.
No more. We added all our engineers to our on-call rota and we set ourselves the lofty target of eliminating all our false alerts. This means if Nagios alerts, you need to act.
As you’d expect, we had a degree of variance in terms of skills – some engineers were perfectly comfortable debugging the entire system, while others were less knowledgeable and less experienced. To ensure that the work was shared equally, we put a simple three-tier system in place – one engineer at Level 1, one at Level 2, one at Level 3.
The Level 1 engineer always managed any incident, they’re the first point of contact. They would acknowledge the alert and communicate to any affected customers. If they needed help to resolve, they escalated to their more experienced/skilled Level 2 or Level 3 colleague. This meant that they got an opportunity to learn, and the burden of on-call wasn’t unfairly balanced towards more experienced team members.
You are on-call for one week at a time, and everybody shares Level 1. Engineers who only do Level 1 are doubled up in the rotation, so they do more shifts at that level as they don’t do shifts at Level 2 or 3. On a team of 15 like ours, this means that your Level 1 shifts come up infrequently. Compared to our previous arrangement where two engineers shared all on-call duties, and they were on their own, this was a huge improvement and much more sustainable.
We also added a widget to our dashing dashboard to indicate who is on call at any given time, so it’s nice and visible to the whole team.

Our dashboard lists the on-call team for that week
Managing Incidents
To help with managing incidents, we set up distribution lists (one for UK and one for US), so it was clear who you needed to email to inform people when an incident did occur – no searching around for email addresses. These were documented along with templates for the incident emails which gave details of the issue, the impact and the timeline to resolution.
In an incident, information is paramount. Information helps people who rely on you make better decisions. Having simple email groups already set up and templates for communications in place, means less thinking when you’re woken up late at night. It also means that people can be informed about incidents sooner, allowing them to react faster.
For example, if a part of our customer service system is down and the on-call team knows that it will be a relatively slow resolution (e.g. if there’s an AWS issue that’s out of our control), we can tell the customer service team early so they can transfer to a back up system. If they’ve no idea what’s going on and how long it’s going to last, that’s going to affect end customers.
Resolving Underlying Issues
It was important to us to reduce our alert volume and remove all false alerts. An early retrospective during this process identified that whilst we all agreed on this goal, the “how” wasn’t clear, so we introduced a new idea – if you’re on call and you get woken up with a false problem, it’s your right and responsibility to come in the next day and work to get things ironed out. This might mean reducing the severity level of an alert, improving the monitoring check itself or working on a bug in the system.
Four weeks after this decision, our false alert volume went through the floor, to the point where we have now eliminated all false alerts. If the phone rings, it’s for real.
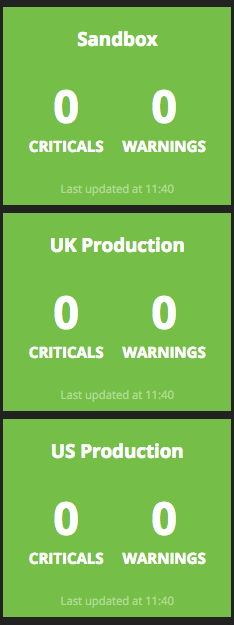
We added Nagios stats to our dashboard, giving easy visibility to everyone.
Without involving the whole team in this, with their wide variety of skills and knowledge of the system, I’m not sure this would have been achieved.
Work Still To Do
During the 2014 peak we deployed throughout our busiest days, including the monumental volumes of Black Friday, and had only 3 minutes of downtime in one small service in the month of December. This was a great success and meant that even as volumes rose significantly, end customers and internal system users were uninterrupted in their work. We invested in removing several single points of failure from our systems before the peak, and it paid off.
We definitely still have areas of improvement. We have a strict uptime target and we exceeded it in December, but past issues meant we missed the target in earlier months. We’ve logged every incident and the associated impact (with severities that we’ve defined) and need still to work through more underlying causes – be it instabilities from service providers and third parties, momentary downtime from component restarts or bugs in our software. In addition, automated testing of Chef recipes is a challenge that we still need to overcome and that’s on the roadmap in 2015.
There will always be more to do… but with a few simple steps, and a commitment from everybody to improve our understanding of operations work, we’ve made a big step forward in a short amount of time.
(CC image by jksphotos)